Deploy an Iris classification model with BentoML#
Classification is one of the most common types of tasks in machine learning. It often involves predicting the class or category of an instance based on its features. In this quickstart, you learn how to deploy an Iris classification model by using the BentoML framework.
Note
The Iris dataset is a classic dataset in machine learning and statistics. It includes 150 instances, each with four attributes - the lengths and the widths of the sepals and petals of Iris flowers. The target variable (or label) is the species of the Iris, which can be one of the three categories (Setosa:0, Versicolor:1, or Virginica:2). For more information, see The Iris Dataset.
To create the Iris classification model, you can either follow the steps in this quickstart or run this project with Google Colab or Docker.
Google Colab. Open the Tutorial Notebook on Colab side by side with this quickstart. As you go through it, you can simply run the sample code from the Colab Notebook. You are able to try out most of the steps on Colab. However, note that Google Colab does not support the use of Docker containers, so you are not able to deploy them in this environment.
Docker. If you have Docker installed, you can run the project from a pre-configured Docker image with:
docker run -it --rm -p 8888:8888 -p 3000:3000 -p 3001:3001 bentoml/quickstart:latest
Prerequisites#
Make sure you have Python 3.8+ and
pipinstalled. See the Python downloads page to learn more.You have a basic understanding of key concepts in BentoML, such as Services and Bentos. We recommend you read Deploy a Transformer model with BentoML first.
(Optional) Install the BentoML gRPC dependencies. This quickstart provides gRPC examples alongside the HTTP ones. However, these examples are optional and you don’t have to know about gRPC to use BentoML. If you are interested in trying the gRPC examples in this quickstart, install the gRPC dependencies for BentoML by running
pip install "bentoml[grpc]".(Optional) Install Docker if you want to containerize the Bento. Some gRPC examples in this quickstart also require Docker.
(Optional) We recommend you create a virtual environment for dependency isolation for this quickstart. For more information about virtual environments in Python, see Creation of virtual environments.
Install dependencies#
Install all dependencies required for this quickstart. The Iris dataset is included in scikit-learn’s datasets module.
pip install bentoml scikit-learn pandas
Save the model to the local Model Store#
Before you create a Service, you need to train a model and save it into the BentoML local Model Store. Create a download_model.py file as below.
import bentoml
from sklearn import svm
from sklearn import datasets
# Load training data set
iris = datasets.load_iris()
X, y = iris.data, iris.target
# Train the model
clf = svm.SVC(gamma='scale')
clf.fit(X, y)
# Save model to the BentoML local Model Store
saved_model = bentoml.sklearn.save_model("iris_clf", clf)
This Python script first loads the Iris dataset and splits it into the feature data X and the target y. X contains the four
measurements for each flower, while y contains the corresponding species of each flower. It then trains the model with the features and
labels from the Iris dataset.
bentoml.sklearn.save_model() saves the trained SVM model to the BentoML Model Store. It is built specifically for the scikit-learn
framework, which is similar to other ML frameworks, such as bentoml.pytorch.save_model. See the Framework Guides to learn more details.
Run this script to download the model.
python download_model.py
Note
It is possible to use pre-trained models directly with BentoML or import existing trained model files to BentoML. See Models to learn more.
The model is now saved in the Model Store with the name iris_clf and an automatically generated version. You can retrieve this model
later by using the name and version to create a BentoML Service. Run bentoml models list to view all available models in the Model Store.
$ bentoml models list
Tag Module Size Creation Time
iris_clf:xuvqdjblrc7xynry bentoml.sklearn 5.98 KiB 2023-07-26 15:47:58
You can manage saved models via the bentoml models CLI command or Python API. For more information, see Manage models.
Create a BentoML Service#
Create a service.py file to define a BentoML Service and a model Runner.
import numpy as np
import bentoml
from bentoml.io import NumpyNdarray
iris_clf_runner = bentoml.sklearn.get("iris_clf:latest").to_runner()
svc = bentoml.Service("iris_classifier", runners=[iris_clf_runner])
@svc.api(input=NumpyNdarray(), output=NumpyNdarray())
def classify(input_series: np.ndarray) -> np.ndarray:
result = iris_clf_runner.predict.run(input_series)
return result
This script first retrieves the latest version of the previously saved iris_clf model from BentoML’s local Model Store and converts it
to a Runner object. Note that you can use a specific tag instead of latest.
It then creates a new BentoML Service named iris_classifier. This Service serves as a container for one or more Runners that can be used to serve machine learning models.
The @svc.api() decorator defines an API endpoint for the BentoML Service. This endpoint accepts input as a NumPy ndarray and returns output also as a NumPy ndarray.
The classify() function uses the model Runner to make predictions, and returns the results. This function is exposed through the Service’s
API and can be used to classify new instances using the model.
Note
Inside the API function, you can define any business logic, feature fetching, and feature transformation code.
Model inference calls are made directly through Runner objects, which are passed into the bentoml.Service(name=.., runners=[..]) call
when creating the Service object.
Serve the model as an HTTP or gRPC server:
$ bentoml serve service:svc
2023-07-26T16:55:43+0800 [INFO] [cli] Prometheus metrics for HTTP BentoServer from "service:svc" can be accessed at http://localhost:3000/metrics.
2023-07-26T16:55:44+0800 [INFO] [cli] Starting production HTTP BentoServer from "service:svc" listening on http://0.0.0.0:3000 (Press CTRL+C to quit)
To start a gRPC server for this Service, you need to enable reflection with --enable-reflection.
Run pip install "bentoml[grpc-reflection]" first to install the dependency and then use bentoml serve-grpc:
$ bentoml serve-grpc service:svc --enable-reflection
2023-07-26T16:53:42+0800 [INFO] [cli] Prometheus metrics for gRPC BentoServer from "service:svc" can be accessed at http://127.0.0.1:3001.
2023-07-26T16:53:43+0800 [INFO] [cli] Starting production gRPC BentoServer from "service:svc" listening on http://0.0.0.0:3000 (Press CTRL+C to quit)
2023-07-26T16:53:43+0800 [INFO] [grpc_api_server:iris_classifier:1] Waiting for runners to be ready...
2023-07-26T16:53:43+0800 [INFO] [grpc_api_server:iris_classifier:1] All runners ready.
Send a prediction request ([5.9, 3, 5.1, 1.8] in the following example) to the Service:
import requests
requests.post(
"http://127.0.0.1:3000/classify",
headers={"content-type": "application/json"},
data="[[5.9, 3, 5.1, 1.8]]",
).text
curl -X POST \
-H "content-type: application/json" \
--data "[[5.9, 3, 5.1, 1.8]]" \
http://127.0.0.1:3000/classify
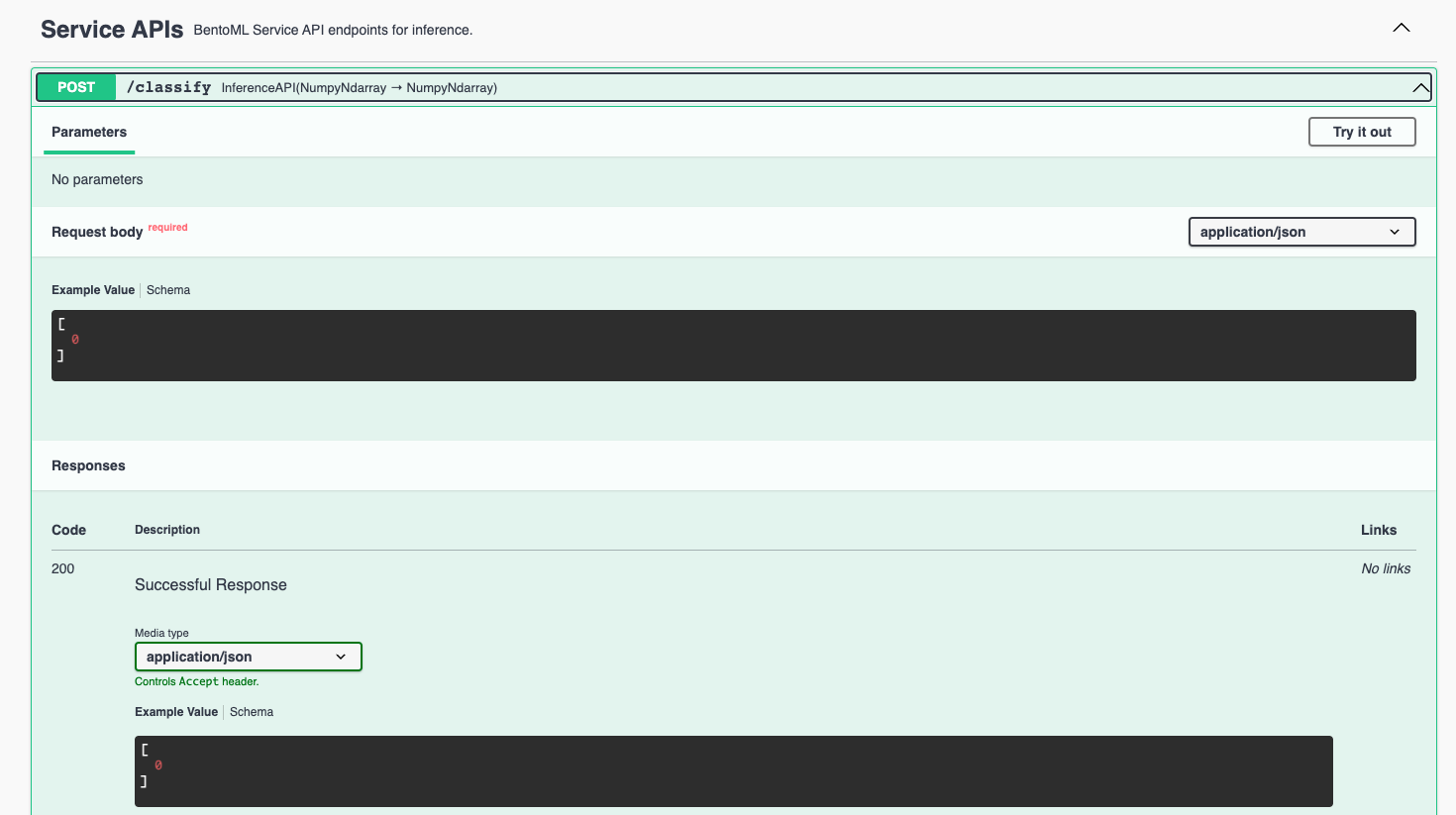
Visit http://127.0.0.1:3000, scroll down to Service APIs, and click Try it out. In the Request body box, enter your prompt and click Execute.
import grpc
import numpy as np
from bentoml.grpc.utils import import_generated_stubs
pb, services = import_generated_stubs()
with grpc.insecure_channel("localhost:3000") as channel:
stub = services.BentoServiceStub(channel)
req: pb.Response = stub.Call(
request=pb.Request(
api_name="classify",
ndarray=pb.NDArray(
dtype=pb.NDArray.DTYPE_FLOAT,
shape=(1, 4),
float_values=[5.9, 3, 5.1, 1.8],
),
)
)
print(req)
Use fullstorydev/grpcurl to send a CURL-like request to the gRPC server.
The following command uses Docker to run the grpcurl command.
docker run -i --rm fullstorydev/grpcurl -d @ -plaintext host.docker.internal:3000 bentoml.grpc.v1.BentoService/Call <<EOM
{
"apiName": "classify",
"ndarray": {
"shape": [1, 4],
"floatValues": [5.9, 3, 5.1, 1.8]
}
}
EOM
docker run -i --rm --network=host fullstorydev/grpcurl -d @ -plaintext 0.0.0.0:3000 bentoml.grpc.v1.BentoService/Call <<EOM
{
"apiName": "classify",
"ndarray": {
"shape": [1, 4],
"floatValues": [5.9, 3, 5.1, 1.8]
}
}
EOM
Use fullstorydev/grpcui to send a request. The following commands use Docker to run the grpcui command. The gRPC web UI is available at http://0.0.0.0:8080/.
docker run --init --rm -p 8080:8080 fullstorydev/grpcui -plaintext host.docker.internal:3000
docker run --init --rm -p 8080:8080 --network=host fullstorydev/grpcui -plaintext 0.0.0.0:3000
The expected output for the prompt [5.9, 3, 5.1, 1.8] is 2, which means the model thinks the category seems to be Virginica.
Build a Bento#
After the Service is ready, you can package it into a Bento by specifying a
configuration YAML file (bentofile.yaml) that defines the build options. See Bento build options to learn more.
service: "service:svc" # Same as the argument passed to `bentoml serve`
labels:
owner: bentoml-team
stage: dev
include:
- "*.py" # A pattern for matching which files to include in the Bento
python:
packages: # Additional pip packages required by the Service
- scikit-learn
- pandas
models: # The model to be used for building the Bento.
- iris_clf:latest
service: "service:svc" # Same as the argument passed to `bentoml serve`
labels:
owner: bentoml-team
stage: dev
include:
- "*.py" # A pattern for matching which files to include in the Bento
python:
packages: # Additional pip packages required by the Service
- bentoml[grpc]
- scikit-learn
- pandas
models: # The model to be used for building the Bento.
- iris_clf:latest
Run bentoml build in your project directory to build the Bento.
$ bentoml build
Locking PyPI package versions.
██████╗ ███████╗███╗ ██╗████████╗ ██████╗ ███╗ ███╗██╗
██╔══██╗██╔════╝████╗ ██║╚══██╔══╝██╔═══██╗████╗ ████║██║
██████╔╝█████╗ ██╔██╗ ██║ ██║ ██║ ██║██╔████╔██║██║
██╔══██╗██╔══╝ ██║╚██╗██║ ██║ ██║ ██║██║╚██╔╝██║██║
██████╔╝███████╗██║ ╚████║ ██║ ╚██████╔╝██║ ╚═╝ ██║███████╗
╚═════╝ ╚══════╝╚═╝ ╚═══╝ ╚═╝ ╚═════╝ ╚═╝ ╚═╝╚══════╝
Successfully built Bento(tag="iris_classifier:awln3pbmlcmlonry").
Possible next steps:
* Containerize your Bento with `bentoml containerize`:
$ bentoml containerize iris_classifier:awln3pbmlcmlonry [or bentoml build --containerize]
* Push to BentoCloud with `bentoml push`:
$ bentoml push iris_classifier:awln3pbmlcmlonry [or bentoml build --push]
To view all available Bentos, run:
$ bentoml list
Tag Size Creation Time
iris_classifier:awln3pbmlcmlonry 78.84 MiB 2023-07-27 16:38:42
Deploy a Bento#
To containerize the Bento with Docker, run:
bentoml containerize iris_classifier:latest
bentoml containerize iris_classifier:latest --enable-features grpc
You can then deploy the Docker image in different environments like Kubernetes. Alternatively, push the Bento to BentoCloud for distributed deployments of your model. For more information, see Deploy Bentos.