Runners#
time expected: 15 minutes
This page articulates on the concept of Runners and demonstrates its role within the BentoML architecture.
What is Runner?#
In BentoML, Runner represents a unit of computation that can be executed on a remote Python worker and scales independently.
Runner allows bentoml.Service to parallelize
multiple instances of a bentoml.Runnable class,
each on its own Python worker. When a BentoServer is launched, a group of runner worker
processes will be created, and run method calls made from the
bentoml.Service code will be scheduled among those runner workers.
Runner also supports Adaptive Batching. For a
bentoml.Runnable configured with batching,
multiple run method invocations made from other processes can be dynamically
grouped into one batch execution in real-time. This is especially beneficial for compute
intensive workloads such as model inference, helps to bring better performance through
vectorization or multi-threading.
Pre-built Model Runners#
BentoML provides pre-built Runners implemented for each ML framework supported. These pre-built runners are carefully configured to work well with each specific ML framework. They handle working with GPU when GPU is available, set the number of threads and number of workers automatically, and convert the model signatures to corresponding Runnable methods.
trained_model = train()
bentoml.pytorch.save_model(
"demo_mnist", # model name in the local model store
trained_model, # model instance being saved
signatures={ # model signatures for runner inference
"predict": {
"batchable": True,
"batch_dim": 0,
}
}
)
runner = bentoml.pytorch.get("demo_mnist:latest").to_runner()
runner.init_local()
runner.predict.run( MODEL_INPUT )
Custom Runner#
For more advanced use cases, BentoML also allows users to define their own Runner classes. This is useful when the pre-built Runners do not meet the requirements, or when the user wants to implement a Runner for a new ML framework.
Creating a Runnable#
Runner can be created from a bentoml.Runnable
class. By implementing a Runnable class, users can create Runner instances that
runs custom logic. Here’s an example (excerpted from one of our example projects)
creating an NLTK runner that does sentiment analysis with a pre-trained model:
from __future__ import annotations
import time
import typing as t
from statistics import mean
from typing import TYPE_CHECKING
import nltk
from nltk.sentiment import SentimentIntensityAnalyzer
import bentoml
from bentoml.io import JSON
from bentoml.io import Text
if TYPE_CHECKING:
from bentoml._internal.runner.runner import RunnerMethod
class RunnerImpl(bentoml.Runner):
is_positive: RunnerMethod
inference_duration = bentoml.metrics.Histogram(
name="inference_duration",
documentation="Duration of inference",
labelnames=["nltk_version", "sentiment_cls"],
buckets=(
0.005,
0.01,
0.025,
0.05,
0.075,
0.1,
0.25,
0.5,
0.75,
1.0,
2.5,
5.0,
7.5,
10.0,
float("inf"),
),
)
polarity_counter = bentoml.metrics.Counter(
name="polarity_total",
documentation="Count total number of analysis by polarity scores",
labelnames=["polarity"],
)
class NLTKSentimentAnalysisRunnable(bentoml.Runnable):
SUPPORTED_RESOURCES = ("cpu",)
SUPPORTS_CPU_MULTI_THREADING = False
def __init__(self):
self.sia = SentimentIntensityAnalyzer()
@bentoml.Runnable.method(batchable=False)
def is_positive(self, input_text: str) -> bool:
start = time.perf_counter()
scores = [
self.sia.polarity_scores(sentence)["compound"]
for sentence in nltk.sent_tokenize(input_text)
]
inference_duration.labels(
nltk_version=nltk.__version__, sentiment_cls=self.sia.__class__.__name__
).observe(time.perf_counter() - start)
return mean(scores) > 0
nltk_runner = t.cast(
"RunnerImpl", bentoml.Runner(NLTKSentimentAnalysisRunnable, name="nltk_sentiment")
)
svc = bentoml.Service("sentiment_analyzer", runners=[nltk_runner])
@svc.api(input=Text(), output=JSON())
async def analysis(input_text: str) -> dict[str, bool]:
is_positive = await nltk_runner.is_positive.async_run(input_text)
polarity_counter.labels(polarity=is_positive).inc()
return {"is_positive": is_positive}
Note
Full code example can be found here.
The constant attribute SUPPORTED_RESOURCES indicates which resources this Runnable class
implementation supports. The only currently pre-defined resources are "cpu" and
"nvidia.com/gpu".
The constant attribute SUPPORTS_CPU_MULTI_THREADING indicates whether or not the runner supports
CPU multi-threading.
Tip
Neither constant can be set inside of the runner’s __init__ or __new__ methods, as they are class-level attributes. The reason being BentoML’s scheduling policy is not invoked in runners’ initialization code, as instantiating runners can be quite expensive.
Since NLTK library doesn’t support utilizing GPU or multiple CPU cores natively, supported resources
is specified as ("cpu",), and SUPPORTS_CPU_MULTI_THREADING is set to False. This is the default configuration.
This information is then used by the BentoServer scheduler to determine the worker pool size for this runner.
The bentoml.Runnable.method decorator is used for creating
RunnableMethod - the decorated method will be exposed as the runner interface
for accessing remotely. RunnableMethod can be configured with a signature,
which is defined same as the Model signatures.
More examples about custom runners implementing their own Runnable class can be found at:
examples/custom_runner.
Reusable Runnable#
Runnable class can also take __init__ parameters to customize its behavior for
different scenarios. The same Runnable class can also be used to create multiple runners
and used in the same service. For example:
import bentoml
import torch
class MyModelRunnable(bentoml.Runnable):
SUPPORTED_RESOURCES = ("nvidia.com/gpu",)
SUPPORTS_CPU_MULTI_THREADING = True
def __init__(self, model_file):
self.model = torch.load_model(model_file)
@bentoml.Runnable.method(batchable=True, batch_dim=0)
def predict(self, input_tensor):
return self.model(input_tensor)
my_runner_1 = bentoml.Runner(
MyModelRunnable,
name="my_runner_1",
runnable_init_params={
"model_file": "./saved_model_1.pt",
}
)
my_runner_2 = bentoml.Runner(
MyModelRunnable,
name="my_runner_2",
runnable_init_params={
"model_file": "./saved_model_2.pt",
}
)
svc = bentoml.Service(__name__, runners=[my_runner_1, my_runner_2])
All runners presented in one
bentoml.Serviceobject must have unique names.
Note
The default Runner name is the Runnable class name. When using the same Runnable
class to create multiple runners and use them in the same service, user must rename
runners by specifying the name parameter when creating the runners. Runner
name are a key to configuring individual runner at deploy time and to runner related
logging and tracing features.
Custom Model Runner#
Custom Runnable built with Model from BentoML’s model store:
from typing import Any
import bentoml
from bentoml.io import JSON
from bentoml.io import NumpyNdarray
from numpy.typing import NDArray
bento_model = bentoml.pytorch.get("spam_detection:latest")
class SpamDetectionRunnable(bentoml.Runnable):
SUPPORTED_RESOURCES = ("cpu",)
SUPPORTS_CPU_MULTI_THREADING = True
def __init__(self):
# load the model instance
self.classifier = bentoml.sklearn.load_model(bento_model)
@bentoml.Runnable.method(batchable=False)
def is_spam(self, input_data: NDArray[Any]) -> NDArray[Any]:
return self.classifier.predict(input_data)
spam_detection_runner = bentoml.Runner(SpamDetectionRunnable, models=[bento_model])
svc = bentoml.Service("spam_detector", runners=[spam_detection_runner])
@svc.api(input=NumpyNdarray(), output=JSON())
def analysis(input_text: NDArray[Any]) -> dict[str, Any]:
return {"res": spam_detection_runner.is_spam.run(input_text)}
Custom Runnable can be also built by extending the Runnable class generated by Model from BentoML’s model store. A full example with custom metrics to monitor the model’s performance can be found at examples/custom_model_runner.
Serving Multiple Models via Runner#
Serving multiple models in the same workflow is also a common pattern in BentoML’s prediction framework. This pattern can be achieved by simply instantiating multiple runners up front and passing them to the service that’s being created. Each runner/model will be configured with its’ own resources and run autonomously. If no configuration is passed, BentoML will then determine the optimal resources to allocate to each runner.
Sequential Runs#
import asyncio
import bentoml
import PIL.Image
import bentoml
from bentoml.io import Image, Text
transformers_runner = bentoml.transformers.get("sentiment_model:latest").to_runner()
ocr_runner = bentoml.easyocr.get("ocr_model:latest").to_runner()
svc = bentoml.Service("sentiment_analysis", runners=[transformers_runner, ocr_runner])
@svc.api(input=Image(),output=Text())
def classify(input: PIL.Image.Image) -> str:
ocr_text = ocr_runner.run(input)
return transformers_runner.run(ocr_text)
It’s as simple as creating two runners and invoking them synchronously in your prediction endpoint. Note that an async endpoint is often preferred in these use cases as the primary event loop is yielded while waiting for other IO-expensive tasks.
For example, the same API above can be achieved as an async endpoint:
@svc.api(input=Image(),output=Text())
async def classify_async(input: PIL.Image.Image) -> str:
ocr_text = await ocr_runner.async_run(input)
return await transformers_runner.async_run(ocr_text)
Concurrent Runs#
In cases where certain steps can be executed concurrently, asyncio.gather can be used to aggregate results from multiple concurrent runs. For instance, if you are running two models simultaneously, you could invoke asyncio.gather as follows:
import asyncio
import PIL.Image
import bentoml
from bentoml.io import Image, Text
preprocess_runner = bentoml.Runner(MyPreprocessRunnable)
model_a_runner = bentoml.xgboost.get('model_a:latest').to_runner()
model_b_runner = bentoml.pytorch.get('model_b:latest').to_runner()
svc = bentoml.Service('inference_graph_demo', runners=[
preprocess_runner,
model_a_runner,
model_b_runner
])
@svc.api(input=Image(), output=Text())
async def predict(input_image: PIL.Image.Image) -> str:
model_input = await preprocess_runner.async_run(input_image)
results = await asyncio.gather(
model_a_runner.async_run(model_input),
model_b_runner.async_run(model_input),
)
return post_process(
results[0], # model a result
results[1], # model b result
)
Once each model completes, the results can be compared and logged as a post processing step.
Another example generating text using three different language models concurrently and then classify each generated paragraph with an classification model can be found at: examples/inference_graph.
Embedded Runners#
BentoML allows you to run Runners in Embedded mode, which means the Runner is embedded in the same process as the API Server.
By default, the API Server and the Runner are independent Python processes that communicate across the wire via either HTTP or gRPC, depending on the configuration. This allows for independent scaling and allocation of resources like GPU instances for both the API Server and the Runner.
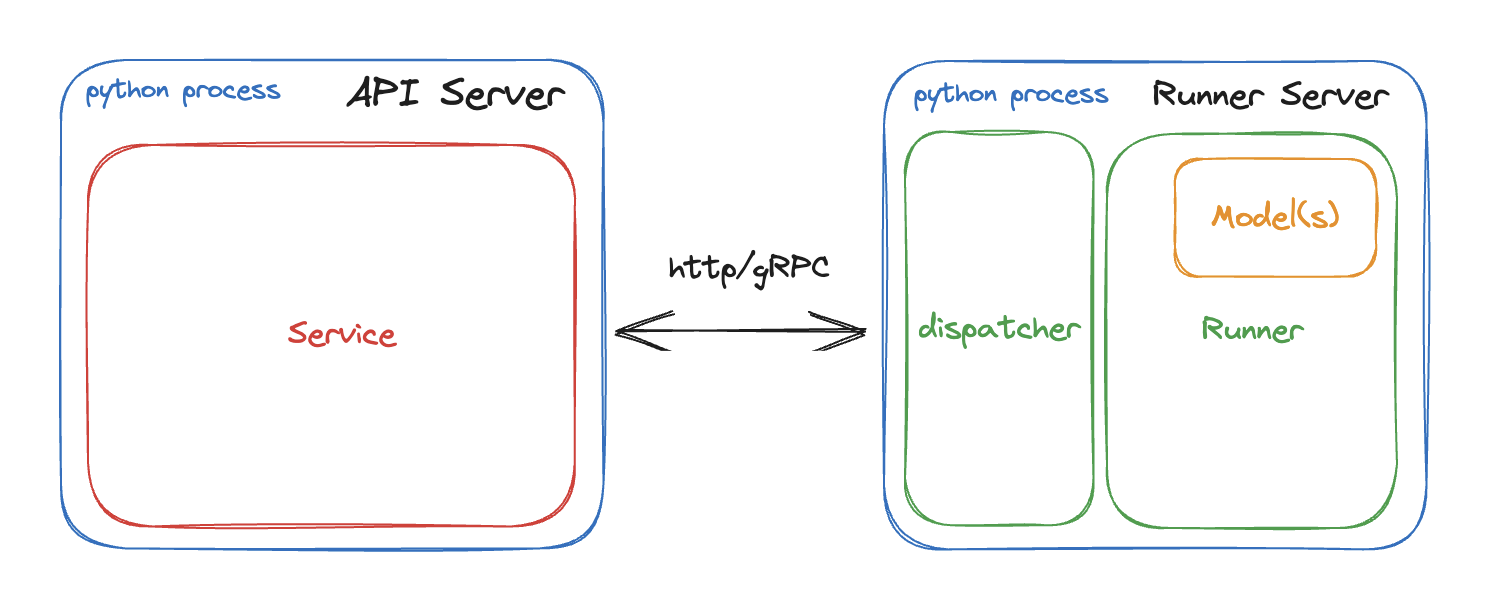
In Embedded mode, the Runner is embedded within the same process as the API Server. This disables the dispatching layer, which means batching
is not available in this mode. To create an embedded Runner, use .to_runner(embedded=True).
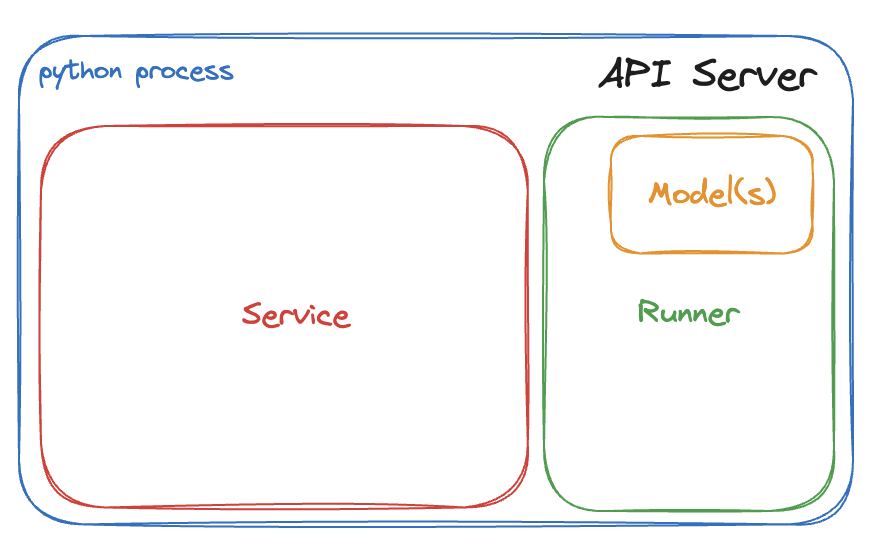
Embedded Runners are designed for use cases with simple and small models where it is better to keep the models in memory. They help simplify your production setups and may offer benefits in certain scenarios. If you have large, CPU-intensive models, running API Servers and Runners in separate processes is a preferable choice since you can scale them independently.
Runner Definition#
Todo
Document detailed list of Runner options
my_runner = bentoml.Runner(
MyRunnable,
runnable_init_params={"foo": foo, "bar": bar},
name="custom_runner_name",
strategy=None, # default strategy will be selected depending on the SUPPORTED_RESOURCES and SUPPORTS_CPU_MULTI_THREADING flag on runnable
models=[..],
# below are also configurable via config file:
# default configs:
max_batch_size=.. # default max batch size will be applied to all run methods, unless override in the runnable_method_configs
max_latency_ms=.. # default max latency will be applied to all run methods, unless override in the runnable_method_configs
runnable_method_configs=[
{
method_name="predict",
max_batch_size=..,
max_latency_ms=..,
}
],
)
Runner Configuration#
Runner behaviors and resource allocation can be specified via BentoML configuration.
Runners can be both configured individually or in aggregate under the runners configuration key. To configure a specific runner, specify its name
under the runners configuration key. Otherwise, the configuration will be applied to all runners. The examples below demonstrate both
the configuration for all runners in aggregate and for an individual runner (iris_clf).
Adaptive Batching#
If a model or custom runner supports batching, the adaptive batching mechanism is enabled by default.
To explicitly disable or control adaptive batching behaviors at runtime, configuration can be specified under the batching key.
Resource Allocation#
By default, a runner will attempt to utilize all available resources in the container. Runner’s resource allocation can also be customized
through configuration, with a float value for cpu and an int value for nvidia.com/gpu. Fractional GPU is currently not supported.
runners:
resources:
cpu: 0.5
nvidia.com/gpu: 1
runners:
iris_clf:
resources:
cpu: 0.5
nvidia.com/gpu: 1
Alternatively, a runner can be mapped to a specific set of GPUs. To specify GPU mapping, instead of defining an integer value, a list of device IDs
can be specified for the nvidia.com/gpu key. For example, the following configuration maps the configured runners to GPU device 2 and 4.
runners:
resources:
nvidia.com/gpu: [2, 4]
runners:
iris_clf:
resources:
nvidia.com/gpu: [2, 4]
For the detailed information on the meaning of each resource allocation configuration, see Resource Scheduling Strategy.
Traffic Control#
Same as API server, you can also configure the traffic settings for both all runners and individual runner.
Specifcally, traffic.timeout defines the amount of time in seconds that the runner will wait for a response from the model before timing out.
traffic.max_concurrency defines the maximum number of concurrent requests the runner will accept before returning an error.
Access Logging#
See Logging Configuration for access log customization.
Distributed Runner with Yatai#
🦄️ Yatai provides a more advanced Runner architecture specifically designed for running large scale inference workloads on a Kubernetes cluster.
While the standalone BentoServer schedules Runner workers on their own Python
processes, the BentoDeployment created by Yatai, scales Runner workers in their
own group of Pods and made it
possible to set a different resource requirement for each Runner, and auto-scaling each
Runner separately based on their workloads.
Sample BentoDeployment definition file for deploying in Kubernetes:
apiVersion: yatai.bentoml.org/v1beta1
kind: BentoDeployment
spec:
bento_tag: 'fraud_detector:dpijemevl6nlhlg6'
autoscaling:
minReplicas: 3
maxReplicas: 20
resources:
limits:
cpu: 500m
requests:
cpu: 200m
runners:
- name: model_runner_a
autoscaling:
minReplicas: 1
maxReplicas: 5
resources:
requests:
nvidia.com/gpu: 1
cpu: 2000m
...
Todo
add graph explaining Yatai Runner architecture